Heavy Tailed Distributions and the States of Randomness
Sections:
I. Normality
II. Portioning
III. Tail Terminology
IV. Mandelbrot’s Seven States of Randomness
V. Compression
VI. The Borderline
VII. Transformation Family
VIII. The Wilderness
IX. Getting More Aggressive
X. The Liquids of Randomness
XI. Stability
XII. Conclusion
I. Normality
The “Normal Distribution” (also called the Gaussian Distribution) is a very useful and well-studied tool for analysing data. It is however often misapplied, despite the efforts of Benoit Mandelbrot and Nassim Taleb to raise awareness of areas where it might be inappropriate to use. One reason people may be tempted to overuse it might be its name, which is a little too suggestive of it being some kind of “standard”, so henceforth I will use its alternative name to avoid perpetuating this any more than is inevitable.
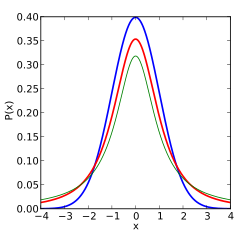
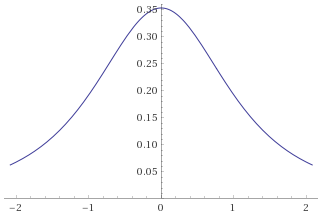
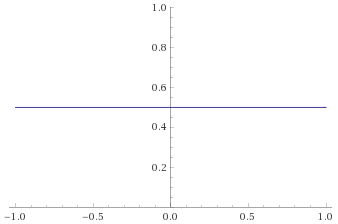
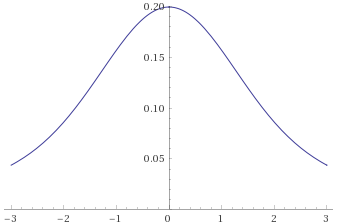
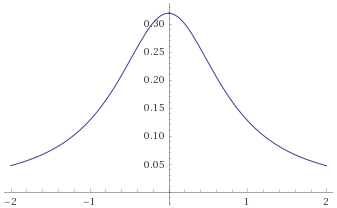
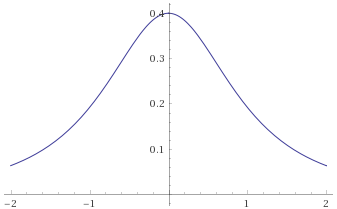
The trouble is, that everyone is so familiar with the Gaussian Distribution, that it is very seductive to shoehorn your data into it and try to use the familiar techniques to analyse your data. When people see a “bell curve”, their first thought is usually “looks like it is Gaussian distributed”, meaning that the data behaves like it has been sampled from the graph below:
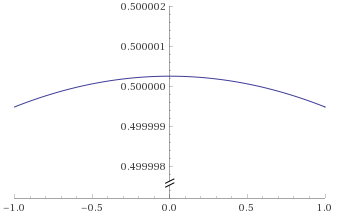
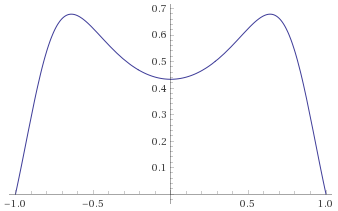
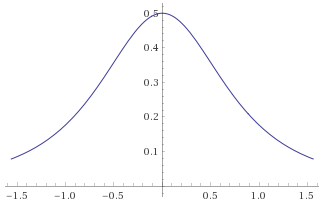
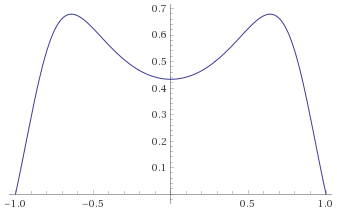
There are however many other distributions that are “bell curves”, and therefore look very similar to a Gaussian Distribution. Some of these behave very differently indeed when compared to the Gaussian Distribution, so it is important not to just default to using the Gaussian Distribution as soon as you see something that looks like a bell curve. By way of example, below are just two examples of distributions that are bell curves, but have very different behaviours to the Gaussian Distribution (in blue). The “Cauchy Distribution” is in green, and the “Students’s T Distribution with 2 degrees of freedom” is in red:
There is a fun bit of analysis that the data scientist Ethan Arsht did, comparing different military commanders throughout history to determine some sort of ranking for them, in a similar vein to baseball sabermetrics. To be clear – I like this analysis. It is a pretty neat insight, and took Ethan Arsht a lot of time and effort to put together, so I am not denigrating him or his conclusions in what I am about to say. It is just a perfect example of the kind of thing I am talking about, that lots of people do without really thinking about it (so, if you’re reading this Ethan, I apologise for using you as an example – there were probably lots of other examples I could have used).
In this article, he writes that the different commanders’ scores “largely adhere to a normal distribution”, and that Napoleon’s score is almost 23 standard deviations above the mean. The probability of an event occurring that is at least 22 standard deviations above the mean whilst being Gaussian Distributed is 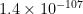


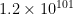
The point of all of this, is that if you get an event that is almost 23 standard deviations above the mean assuming a Gaussian Distribution, then your data is NOT Gaussian Distributed. Even if you get an event “only” 6 standard deviations above (or below) the mean, this has a probability of around 1 in a billion, so unless you have an enormous amount of data already, it is pretty reasonable to suggest that your data isn’t as well behaved as a Gaussian Distribution would be. There is a good post on Slatestarcodex (still available in this archive) on conceptualising very small probabilities, which is useful for gaining a bit of intuition on the matter. Effectively, if the data was truly Gaussian Distributed, the outcome above is so vanishingly unlikely that it becomes more likely that you have either made a mistake in the analysis, or are simply hallucinating the whole thing.
II. Portioning
The most important way in which these other distributions differ from the Gaussian Distribution is how “heavy” their “tails” are. This basically means how quickly or slowly the probability declines as you move out to the far right or left of the distribution, and should be fairly easy to pick out on the graph above. If a distribution has heavier tails than a Gaussian Distribution, then more extreme events are more likely. Importantly, this is not the same as variance – a Gaussian Distribution with a high variance might permit a wide range of events with a reasonable probability, but an event that is 6 standard deviations above the mean is still around 1 in a billion. A heavy tailed distribution could be constructed to have the same variance, but such an event would be significantly more likely – perhaps 1 in 1000.
A useful concept to get across the idea of heavy tails is referred to as “portioning”. People’s heights can be considered to be roughly Gaussian distributed (we can ignore the fact that sexual dimorphism makes the distribution of heights bimodal, as this doesn’t significantly impact the tails). If someone selects two people at random from a population, add their heights together, and that sum is all that they tell you, you can make an educated guess about what you expect the individuals’ heights to be. If the sum is unusually large, say 400cm, you know that 200cm people are quite rare – around 1 in 1000, so picking 2 of them would be 1 in a million. On the other hand, whilst it could be an average height person at 175cm and an extremely tall person at 225cm, people that tall are more like 1 in 100 million, so given that the sum you were given is 400cm, unlikely though that result was, it is much more likely that the people measured were both very tall, around 200cm each, than it is that they managed to measure one of the vanishingly few people that is around 225cm tall. This is described as “even portioning”.
Wealth however is distributed according to a heavier tailed distribution – if you did the same thing but with people’s wealth rather than their height, and were given the sum of $1 billion, it would be possible for it to be two people each with wealth around $500 million each, but each of these is 1 in 300,000 making the probability of picking 2 of them 1 in 90 billion. Picking a person worth around $1 billion would be around 1 in 600,000 making it far more likely that the people were 1 average person and 1 billionaire, given the sum that you were told. This is described as the “concentrated portioning” – the majority of the sum is concentrated into one of the portions making up the sum. This concentrated portioning is a feature of heavier tails, and can generate useful intuitions about heavier tailed randomness. If you add more people/samples to the sum, the portioning may even out, with several samples contributing significantly to the sum – this is referred to as having concentrated short-run portioning but having even long-run portioning. If the tails are even heavier though, one sample could still dominate, contributing most of the sum’s value, no matter how many samples are summed together – this is referred to as concentrated long-run portioning.
III. Tail Terminology
Along the road to generating a structure from which to better perceive these concepts, there is some existing terminology that needs discussing, if only to immediately ignore it in favour of something better (seriously, feel free to skip to the next section).
Heavy tails technically means any tail that decays more slowly than that of the Exponential Distribution (it is defined in slightly more complicated and rigorous terms involving it’s “moment generating function” 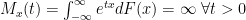
Long tails are defined slightly differently, being distributions that obey the following formula: ![\small \lim_{x\to\infty}\frac{P[X>x+t]}{P[X>x]}=1](https://s0.wp.com/latex.php?latex=%5Csmall+%5Clim_%7Bx%5Cto%5Cinfty%7D%5Cfrac%7BP%5BX%3Ex%2Bt%5D%7D%7BP%5BX%3Ex%5D%7D%3D1+&bg=ffffff&fg=000&s=0&c=20201002)
Sub-exponential tails are defined differently again, being distributions satisfying the formula: ![\small \lim_{x\to\infty}\frac{P[X_1+X_2\leq x]}{P[X\leq x]}=2](https://s0.wp.com/latex.php?latex=%5Csmall+%5Clim_%7Bx%5Cto%5Cinfty%7D%5Cfrac%7BP%5BX_1%2BX_2%5Cleq+x%5D%7D%7BP%5BX%5Cleq+x%5D%7D%3D2+&bg=ffffff&fg=000&s=0&c=20201002)
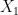
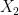
We now have three terms that are almost equivalent to each other, but not quite. This is not useful for generating any kind of helpful structure, and it is not too surprising that heavy tails and long tails are used fairly interchangeably in most contexts. Aside from highly contrived distributions that are constructed solely to prove that the different definitions are not entirely equivalent, all commonly used distributions that are members of one of these sets are members of the other two sets as well. As being heavy tailed is the most inclusive set, I have chosen to use this terminology, but we ideally need something more informative.
One final term that can be used is fat tails. This is sometimes used to mean a tail that decays like (or slower than) a power law, such as a Pareto Distribution. This would make it refer to a significantly heavier tail than many sub-exponential distributions, and could potentially be a useful classification if it could be used unambiguously. Unfortunately, it is also often used synonymously with heavy tails, which removes any useful disambiguation properties it could have had.
IV. Mandelbrot’s Seven States of Randomness
Thankfully Benoit Mandelbrot developed a system of classification for types of randomness that allows us to classify different types of heavy tails much more reliably. It is still not particularly widely known about, but recent efforts by Nassim Taleb have spread the concept slightly beyond the academic community. The main issue with the classification system as a conceptual structure is that it is not particularly easy to visualise, and requires a relatively deep understanding of probability and mathematical terminology to work with. Mandelbrot started with 3 states – Mild, in which short-run portioning was even; Slow, in which short-run portioning was concentrated but long-run portioning became even; and Wild, in which long-run portioning remained concentrated. He then expanded upon this and in his book “Fractals and Scaling in Finance” Chapter E5, section 4.4, Mandelbrot lists “Seven States of Randomness”, which I have paraphrased below:
- Proper Mild Randomness
- Short-run Portioning is even for N=2
- Borderline Mild Randomness
- Short-run Portioning is concentrated
- Long-run Portioning becomes even, for some finite N
- The nth root of the nth moment grows like n
- Delocalised Slow Randomness
- The nth root of the nth moment grows like a power of n
- Localised Slow Randomness
- The nth root of the nth moment grows faster than any power of n
- All moments still finite
- Pre-wild Randomness
- Moments grow so fast that some higher moments are infinite
- The 2nd moment (variance) is still finite
- Long-run Portioning still becomes even, for a large enough finite N
- Wild Randomness
- Even the 2nd moment is infinite, so the variance is not defined
- There exists some moment (possibly fractional)
that is still finite
- Long-run Portioning is concentrated for all N
- Extreme Randomness
- All moments
- All moments
The first couple of these make sense, given our understanding of portioning, but then they start being defined in relation to moments, so before moving on, let’s take pause to understand what this is saying (or skip to the next section, if you want to see a more intuitive approach). As a side-note, it is worth mentioning that “Delocalised” and “Localised” also refer to properties of moments of functions in these classes, however it will not be necessary to delve into the reasons behind this terminology, as other ways of defining these categories may be much more straightforward.
Firstly, the area under a distribution’s Probability Density Function is always 1 by necessity. The x-axis covers every possible eventuality, therefore the probability of an event occurring that is anywhere on the x-axis is a certainty. This means that for any Probability Density Function 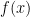

The mean of a distribution is calculated with the formula 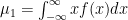
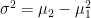

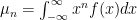
This is the starting point for Mandelbrot’s definition of the later States of Randomness – if we create a new function based on these moments, giving us the xth root of the xth moment: 
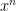

The way to reliably compare functions in this way, is to look at their behaviour as x tends to infinity. If 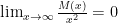

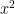
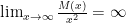
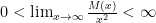
Usefully, Mandelbrot has established that the growth rate of this function maps directly to the rate of decay of the right-hand tail of their corresponding Complimentary Cumulative Distribution Function (or Survival Function). Given a random variable X’s Probability Density Function 

Its Survival Function is then:

Mandelbrot’s insight is the following:
- If
grows like
, as per Borderline Mild Randomness, this is equivalent to the Survival Function
decaying like
, therefore the Exponential Distribution is necessarily a Borderline Mild distribution.
- If
, as per Delocalised Slow Randomness, this is equivalent to the Survival Function decaying like
for some
. This is a family of functions that decay more slowly than
- If
, as per Localised Slow Randomness, this is equivalent to the Survival Function decaying like
for some
- If
, but grows so quickly that it becomes infinite for some finite value of x, as per Pre-Wild Randomness, this is equivalent to the Survival Function decaying like
for some
. This means that the tails of the Probability Density Function
. Notably, the previous state’s decay rate of
this simplifies to
. As long as
- By allowing for the second moment to become infinite as well, Wild Randomness is the domain of distributions whose Survival Function’s tails decay like
.
- Mandelbrot writes that Extreme Randomness is something that he “never encountered in practice”. The fact that such a distribution would not even have fractional moments is equivalent to the statement that its Survival Function decays slower than any power law, even fractional powers. This means that it must decay logarithmically.
After all of that, it is still difficult to gain an intuition about these states. The heuristic of even and concentrated portioning provides a basis for the original 3 states of Mild, Slow and Wild, but even then, if you are given the formula for a distribution, it is not obvious how you might go about classifying it. My aim is to come up with a way to more easily visualise how each of these classes of distributions behaves. Importantly, what I am doing below is not going to be a mathematical proof – it may well be provable, and the methodology below may suggest an approach, but I am only seeking to expound a heuristic here.
V. Compression
Given a particular distribution, it would be useful to be able to apply a transform to it that would bring the tails that disappear off towards infinity into a finite realm where they can be inspected. The idea here is to effectively “compress” the tails of the distribution into a finite interval in some sort of consistent way so that different distributions can be compared. Firstly, to keep things consistent and straightforward I will only use distributions that are either defined over the domain 

One way to do this, is to find a function 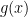



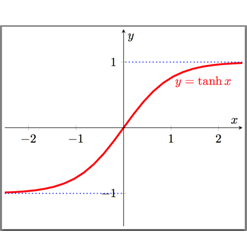
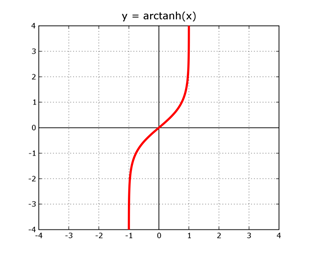
Because the output of 
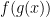

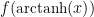
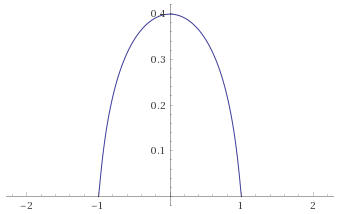
This looks like it is doing what we want, but there is a little housekeeping left to do.
Firstly, we don’t want distributions with the same tail properties but different scales to behave differently under this transformation. For instance, this transform would look different if we used a Gaussian Distribution with variance 2 rather than 1, even though the choice of variance doesn’t change the tail behaviour. This also cannot be dealt with by simply adjusting for the variance of the distribution, as distributions classed as “Wild” do not have a well-defined variance. We can however use the median of right-handed distributions, and the third quartile of symmetric distributions. Keeping zero mapping to zero, we can map the median of a right handed distribution defined on 




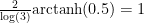
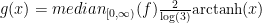

Secondly, the area under this graph is clearly not 1, so we need to adjust the transformation to make it preserve the area. This turns out to be very easily doable by an application of the chain rule – we know that 
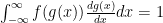

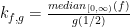
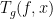


This is still a very easy to apply transformation and we can see how it treats the Gaussian Distribution now that it has been adjusted to renormalize horizontal scaling and preserve the area under the curve.
The Gaussian Distribution (mean 0, variance 1), given by the probability density function 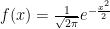
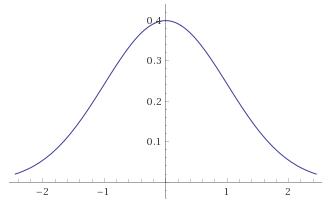
You can easily reproduce the second plot by typing the following into Wolfram Alpha, noting that the Gaussian Distribution with mean 0 and variance 1 has its third quartile at 0.67449 so you have 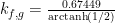
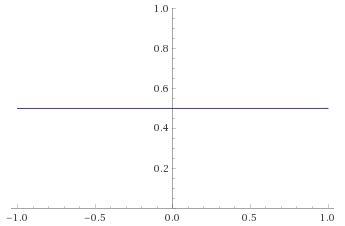
plot 1/sqrt(2π) e^(-g^2/2) dg/dx substitute g=0.67449 arctanh(x)/arctanh(0.5) from x=-1..1 y=0..0.6
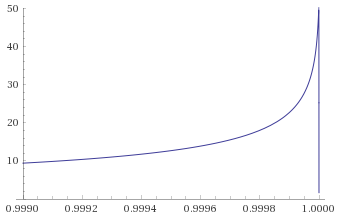
Importantly, this function is still 0 at x=1 and x=-1. Furthermore, as the area under the graph has been preserved by the transformation, the area under the curve between say x=0.99 and x=1 is the same as the area under the original un-transformed probability density function between 
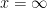

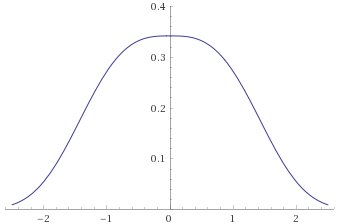
In terms of Mandelbrot’s seven states, the Gaussian Distribution falls into the Mild class. The transformation’s behaviour at 
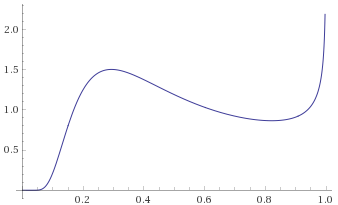
Generalised Gaussian Distribution with shape parameter 3 [before, after] – this distribution has even lighter tails than the Gaussian Distribution, which is reflected in the way that the “shoulders” of the second graph fall towards zero earlier than they did for the Gaussian Distribution:
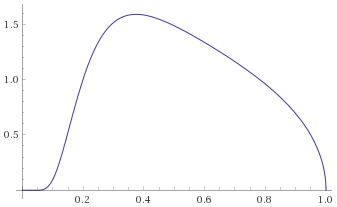
Maxwell Distribution (also known as the Chi Distribution with 3 degrees of freedom) [before, after]:
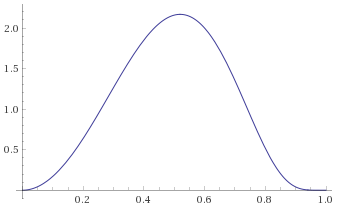
Rayleigh Distribution with scale parameter 1 (also known as the Chi Distribution with 2 degrees of freedom) [before, after] – note again that a different scale parameter results in the same transformed graph – the Rayleigh Distribution with scale parameter 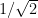
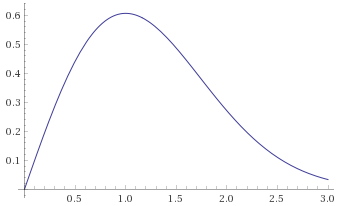
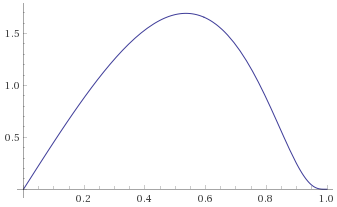
Chi-Squared Distribution with 6 degrees of freedom (also known as the Gamma Distribution with shape parameter 3 and scale parameter 2) [before, after] – again, a Gamma Distribution with shape parameter 3 and scale parameter 1/3 is mapped to the same shape:
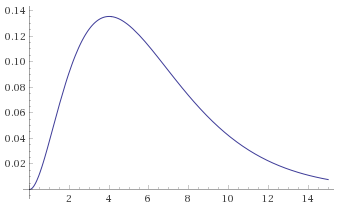
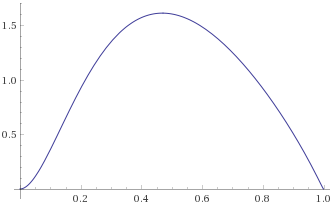
Chi-Squared Distribution with 3 degrees of freedom (also known as the Gamma Distribution with shape parameter 1.5 and scale parameter 2) [before, after]:
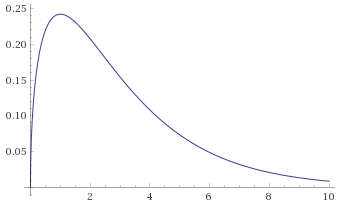
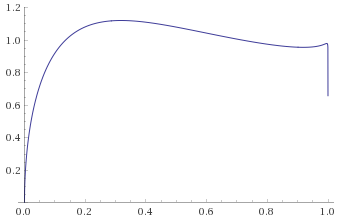
All of the above distributions are in the Mild category, and conveniently all go to zero at 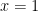
VI. The Borderline
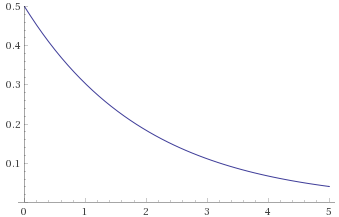
What happens when we try a few Borderline Mild distributions?
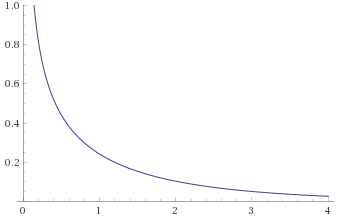
Exponential Distribution, scale ½ (also Gamma Distribution, shape 1, scale 2; Weibull Distribution, shape 1 scale 2; Chi Squared Distribution, 2 degrees of freedom) [before, after]:
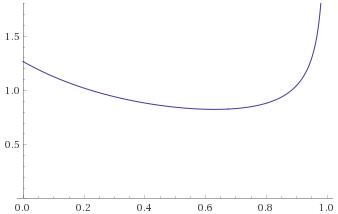
Chi-Squared Distribution, 1 degree of freedom (also Gamma Distribution, shape 0.5, scale 2) [before, after]:
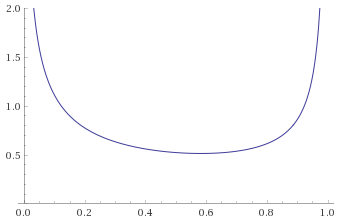
Laplace Distribution (also known as Generalised Gaussian Distribution with shape parameter 1) [before, after] – this distribution is a scaled exponential distribution reflected about the y-axis:
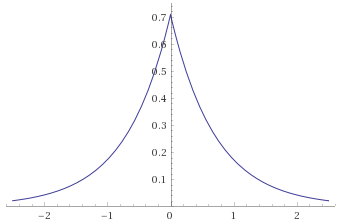
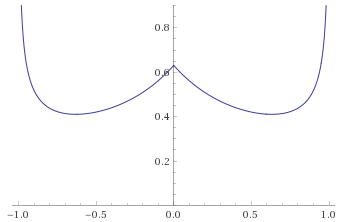
Logistic Distribution [before, after]:
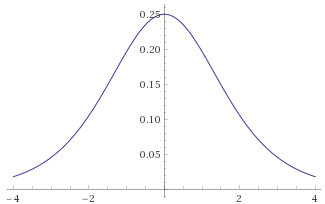
None of these distributions go to zero at 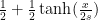








Going forwards, as shorthand I shall refer to a transformation taking a distribution to zero at
VII. Transformation Family
The function we have used so far
The most fundamental properties that 
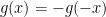
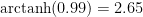


We can construct a faster growing function by multiplying 

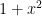

We can of course multiply it by this again and again, building up a whole family of transformations, each growing faster than the last:






But there is still further that we can go; 

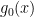





This is still not the fastest 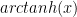






Finally, we can construct yet another that will grow faster than any of these (it would of course be possible to construct yet faster ones, but this will suffice for our purposes here):

Armed with this array of transformations, we can return to looking at some more heavy tailed distributions.
VIII. The Wilderness
In his book “Fractals and Scaling in Finance”, Mandelbrot mentions that the Slow states of randomness (Borderline Mild, Slow Delocalised, Slow Localised and Pre-Wild) are more subtle to deal with, and I quite agree. As such, I shall start looking at the Wild states first. To remind ourselves; Wild Randomness occurs when even the 2nd moment is infinite, so the variance is not defined. There exists some moment (possibly fractional) 
In fact, I am inclined to draw a further distinction between the states of randomness for which Long-run Portioning is concentrated for all N (those being Wild and Extreme according to Mandelbrot). The Wild category as defined by Mandelbrot has a natural dividing line at the point where the 1st moment ceases to be defined – splitting the category into those distributions with a mean, and those whose mean is also undefined. It is undeniable that a distribution whose mean is undefined is significantly more pathological than one which has a mean, so it makes sense to split these out. If you are sampling from a distribution whose mean is undefined and you try to take the mean of your sample, you can calculate it, but as you take more samples the sample mean you are calculating will never converge to a value – the samples you take will occasionally be so vast that it will shift the mean significantly in a random direction, no matter how many samples you have already taken.
If we continue to refer to the state of randomness with undefined variance but valid mean as Wild Randomness, we can refer to the state with undefined mean but some valid fractional moment as Aggressively Wild randomness, or perhaps Aggressive randomness for short. It is worth noting that this Aggressive state is different from the Extreme state, for which not even fractional moments exist. I have seen it written or implied occasionally that the Extreme category includes anything which has an undefined 1st moment, but this is incorrect as per Mandelbrot’s original framing of the states.
When he says that he never encountered Extreme randomness in practice, he wasn’t forgetting things like the Cauchy Distribution and the Lévy Distribution, both of which are relatively well known distributions with an undefined mean. Unlike genuinely Extreme randomness however, they do have fractional moments, for example the 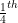

Initially, let’s restrict ourselves to the Wild category (by which I mean not the Aggressive category). To start with, let’s see what happens when we use 

Student’s T Distribution, 2 degrees of freedom [before, transform 1, transform 2]:
Arcsinh-Logistic Distribution, shape parameter 2 (this is the distribution of a random variable, the inverse hyperbolic sine of which is distributed like a Logistic Distribution with scale parameter 2) [before, transform 1, transform 2]:
Pareto Distribution, shape parameter 2 [before, transform 1, transform 2]:
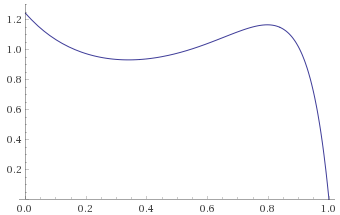
Fisk Distribution, shape parameter 1.5 (also Log-Logistic Distribution shape 1.5 – this is the distribution of a random variable, the logarithm of which is distributed like a Logistic Distribution with scale parameter 1.5) [before, transform 1, transform 2]:
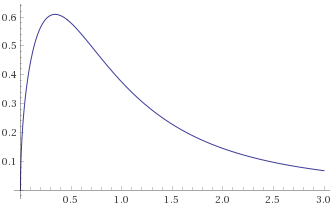
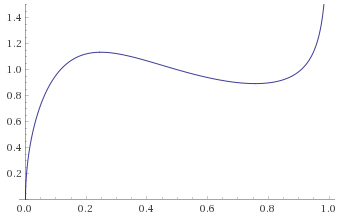
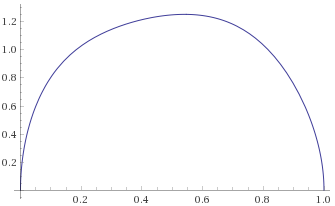
Inverse-Chi-Squared Distribution, 3 degrees of freedom (also Inverse-Gamma Distribution, shape 1.5, scale 0.5) [before, transform 1, transform 2]:
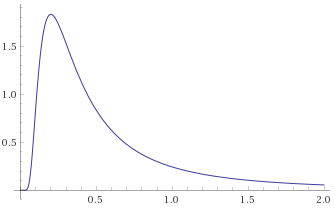
We can see from all of these, that the
IX. Getting More Aggressive
We can now see whether the state of Aggressive randomness behaves differently (spoilers – it does). Let’s use 

Slash Distribution [before, transform 1, transform 2]:
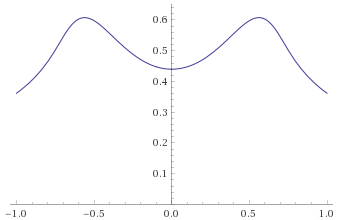
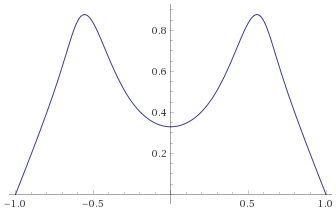
Cauchy Distribution (also Student’s T Distribution, 1 degree of freedom; Stable Distribution, stability parameter 1, skewness parameter 0) [before, transform 1, transform 2]:
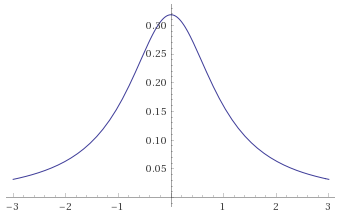
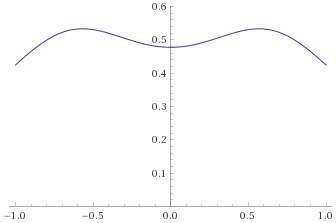
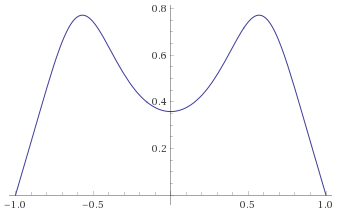
Arcsinh-Logistic Distribution, shape parameter 1 [before, transform 1, transform 2]:
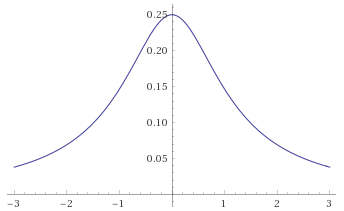
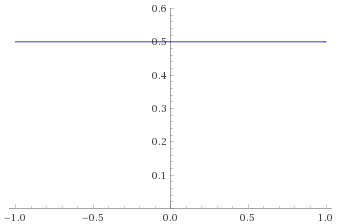
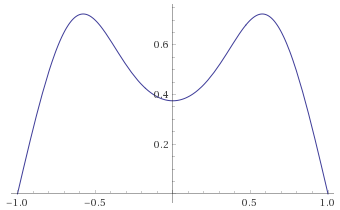
Student’s T Distribution, 0.5 degrees of freedom [before, transform 1, transform 2, transform 3]:
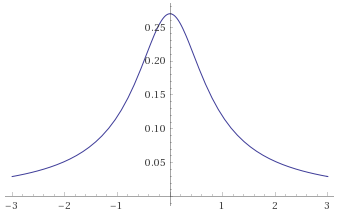
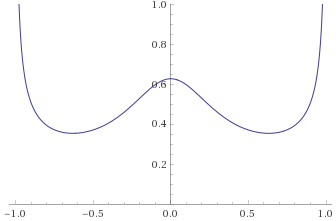
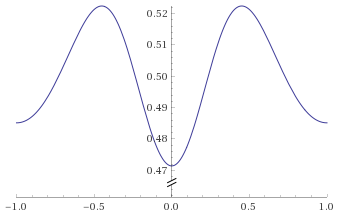
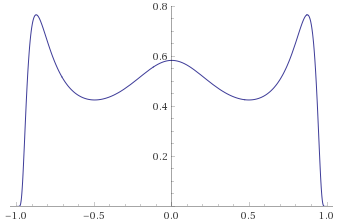
Pareto Distribution, shape parameter 1 (also Fisk Distribution, shape 1; Log-Logistic Distribution, shape 1) [before, transform 1, transform 2]:
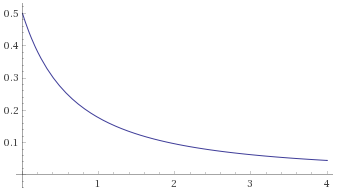
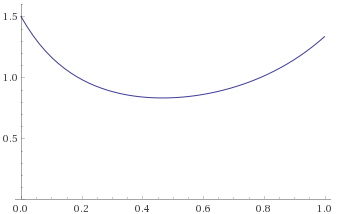
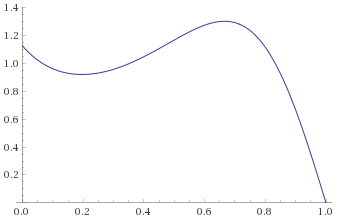
Lévy Distribution (also Inverse-Chi-Squared Distribution, 1 degree of freedom; Inverse-Gamma Distribution, shape 0.5, scale 0.5; Stable Distribution, stability parameter 0.5, skewness parameter 1) [before, transform 1, transform 2, transform 3]:
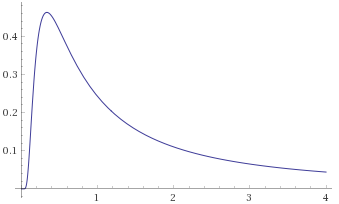
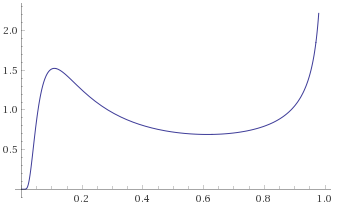
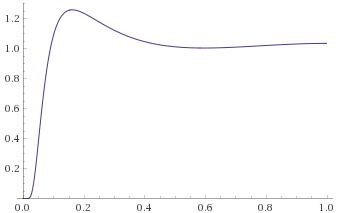
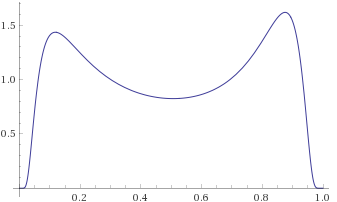
We can see that 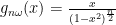

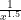
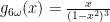
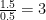
Now we just need to make sure that Extreme distributions behave yet differently, to make sure that we can tell the difference using these transformations. We can use
Arcsinh-Cauchy Distribution (this is the distribution of a random variable, the inverse hyperbolic sine of which is distributed like a Cauchy Distribution) [before, after]:
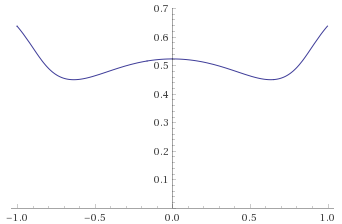
Log-Cauchy Distribution (this is the distribution of a random variable, the logarithm of which is distributed like a Cauchy Distribution) [before, after]:
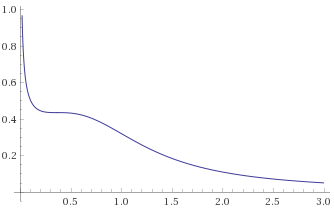
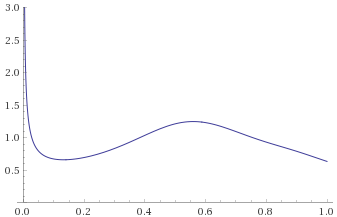
Unlike the Aggressive distributions, these Extreme distributions are not tamed by this transformation, which is useful as it allows us to distinguish between the different categories.
X. The Liquids of Randomness
We have now picked the low hanging fruit. Rather poetically, Mandelbrot likens the states of randomness to the states of matter – Solid, Liquid and Gas compared with Mild, Slow and Wild. Mild randomness behaves metaphorically like a solid – unsurprising and inert – the extremes in your data/model won’t really be extreme at all. Wild randomness (encompassing Wild, Aggressive and Extreme) behaves like a gas – all over the place, but obeying its own rules that make sense – extremes are the defining feature of your data/model. Slow randomness (encompassing Borderline Mild, Slow Delocalised, Slow Localised and Pre-Wild) he compares with a liquid – a strange mixture of both behaviours, sometimes acting in ways that a solid might (falling from a height, water is as unforgiving as concrete/with enough data, you find that the extremes are effectively bounded), but other times behaving similar to a gas (liquids get everywhere/with a small enough sample, the extremes dominate enough to skew the data). It is clear from this, that Mandelbrot considers Slow randomness to be tricky to deal with.
We have already established the boundaries of Slow randomness (again – heuristically, not by proof). We know that 
Thankfully, in between these two functions, we have already established that there are a couple of families of functions that may be instructive: 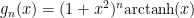
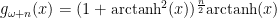
![\displaystyle g_{2\omega-3}(x)=\frac{x}{\sqrt[3]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7B2%5Comega-3%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5B3%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle g_{2\omega-4}(x)=\frac{x}{\sqrt[4]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7B2%5Comega-4%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5B4%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle g_{2\omega-n}(x)=\frac{x}{\sqrt[n]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_%7B2%5Comega-n%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5Bn%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
No matter how large n becomes, there will be a point after which 
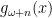
Having just dealt with the Wild category, we can start with the distributions exhibiting Pre-Wild randomness. Many of these look like power laws, similar to the Wild distributions that were tamed by ![\small g_{2\omega-n}(x)=\frac{x}{\sqrt[n]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Csmall+g_%7B2%5Comega-n%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5Bn%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\small g_{2\omega-8}(x)=\frac{x}{\sqrt[8]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Csmall+g_%7B2%5Comega-8%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5B8%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\small g_{2\omega-4}(x)=\frac{x}{\sqrt[4]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Csmall+g_%7B2%5Comega-4%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5B4%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
Student’s T Distribution, 5 degrees of freedom [before, transform 1, transform 2, transform 3]:
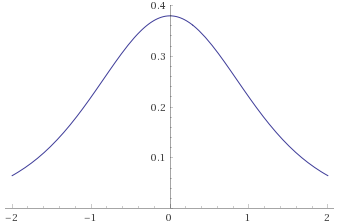
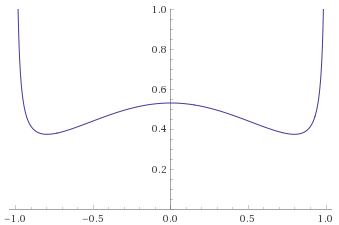
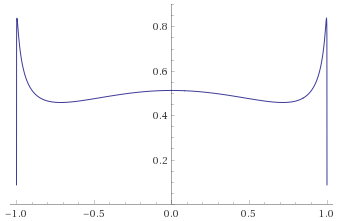
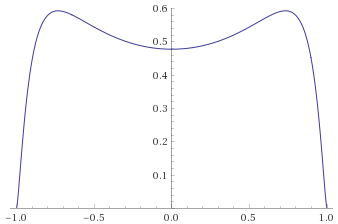
Student’s T Distribution, 3 degrees of freedom [before, transform 1, transform 2, transform 3]:
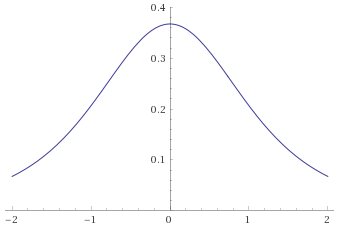
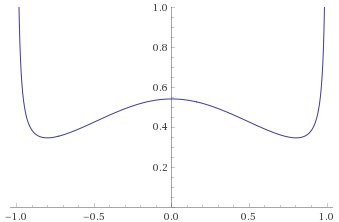
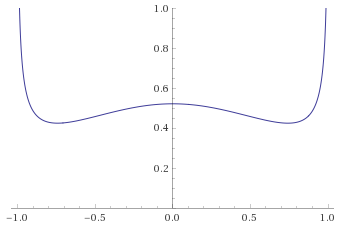
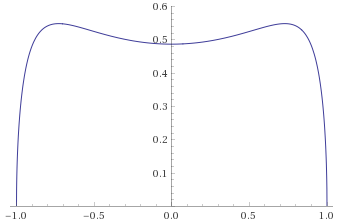
Pareto Distribution, shape 7 [before, transform 1, transform 2, transform 3]:
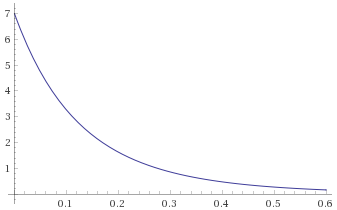
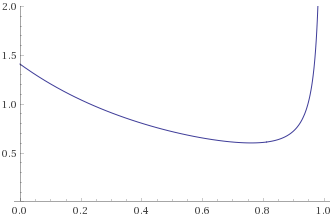
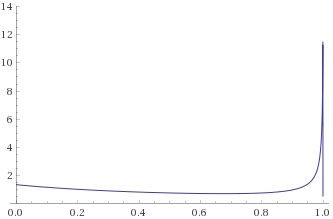
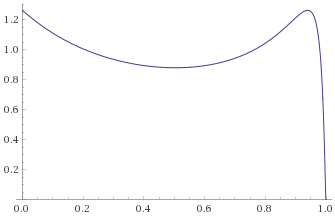
Fisk Distribution, shape 3 (also Log-Logistic Distribution, shape 3) [before, transform 1, transform 2, transform 3]:
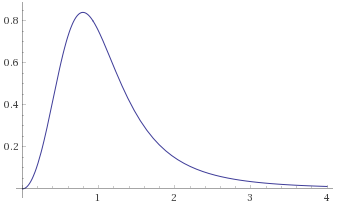
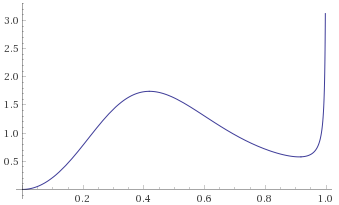
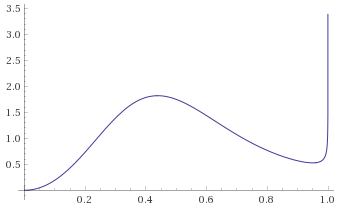
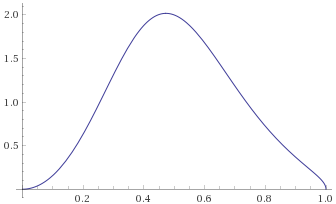
Inverse-Chi-Squared Distribution, 5 degrees of freedom (also Inverse-Gamma Distribution, shape 2.5, scale 0.5) [before, transform 1, transform 2, transform 3]:
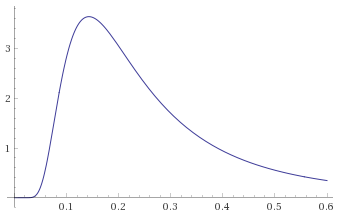
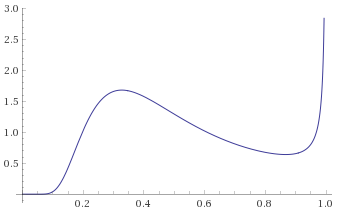
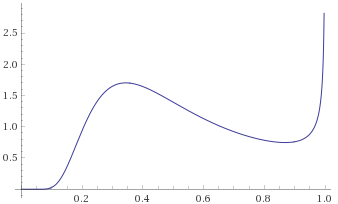
In a similar manner to the Aggressive category, we can suggest a fairly sensible rule of thumb. It looks like a Probability Density Function that behaves like 
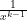
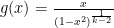

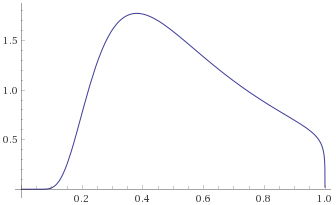
![\small g_{2\omega-9}(x)=\frac{x}{\sqrt[9]{1-x^2}}](https://s0.wp.com/latex.php?latex=%5Csmall+g_%7B2%5Comega-9%7D%28x%29%3D%5Cfrac%7Bx%7D%7B%5Csqrt%5B9%5D%7B1-x%5E2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
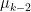
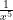

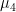
The issue with this, is that although we have that a Pre-Wild distribution will be tamed by
Skipping to the other end of the spectrum of Slow randomness, we can look at distributions that we know are Borderline Mild (the same ones as in the borderline section). We can hypothesise that they will be tamed by 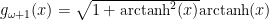

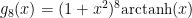
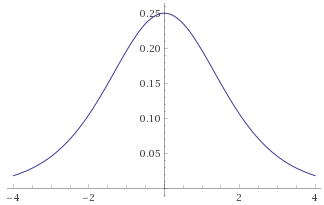
Logistic Distribution [before, transform 1, transform 2, transform 3]:
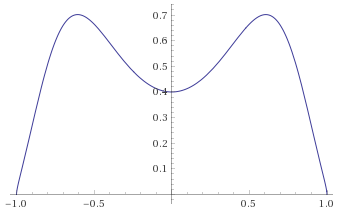
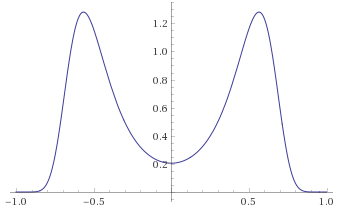
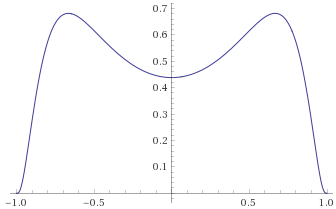
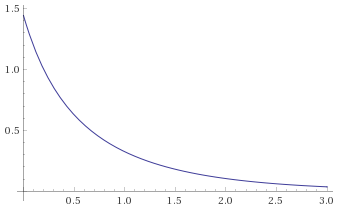
Exponential Distribution [before, transform 1, transform 2, transform 3]:
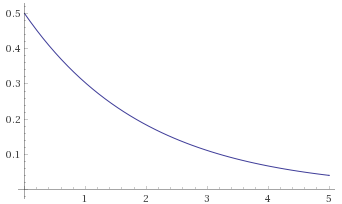
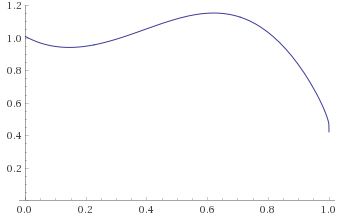
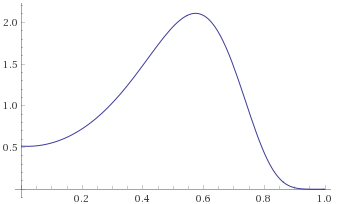
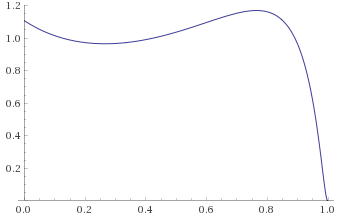
Exponential-Logarithmic Distribution, shape 0.5, scale 1 [before, transform 1, transform 2, transform 3]:
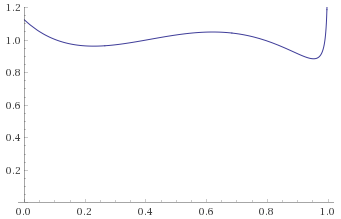
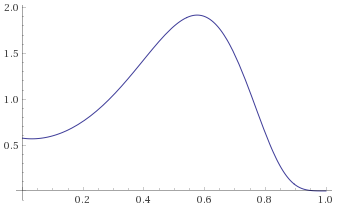
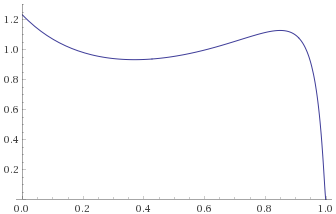
Chi-Squared Distribution with 1 degree of freedom [before, transform 1, transform 2, transform 3]:
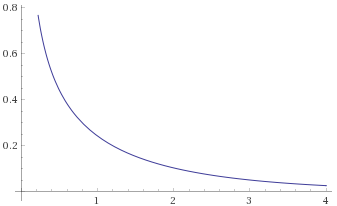
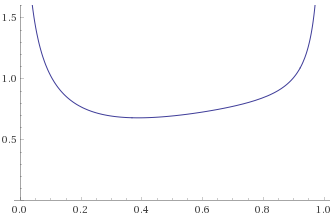
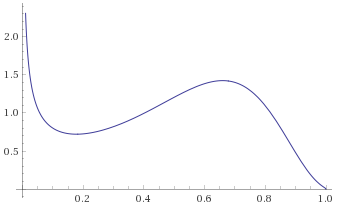
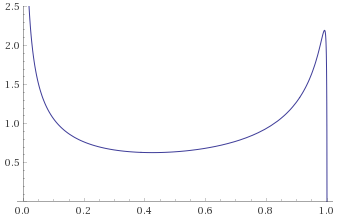
With the Chi-Squared Distribution with 1 degree of freedom, it becomes apparent what the problem is. As per Mandelbrot, all Gamma Distributions with shape parameter 

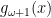
We can similarly hypothesise that Slow Delocalised randomness is tamed by 
Generalised Gaussian Distribution, shape ½ [before, transform 1, transform 2]:
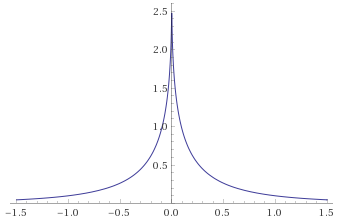
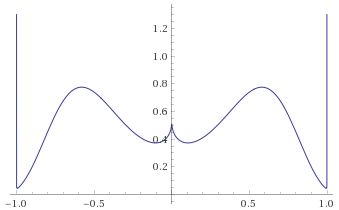
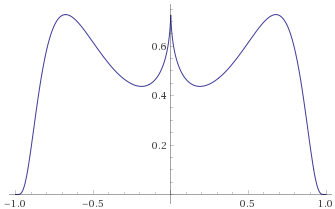
Generalised Gaussian Distribution, shape ¼ [before, transform 1, transform 2]:
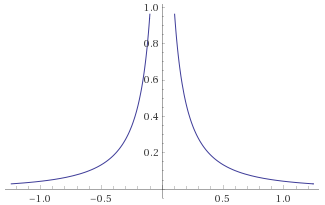
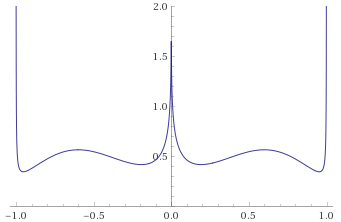
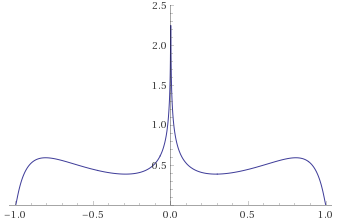
Weibull Distribution, shape ½ [before, transform 1, transform 2]:
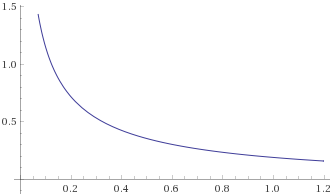
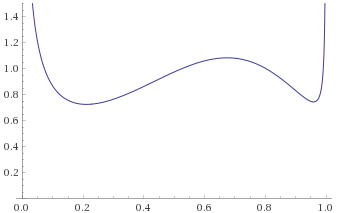
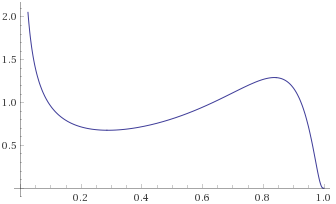
Generalised Exponential Distribution, shape ¼ [before, transform 1, transform 2]:
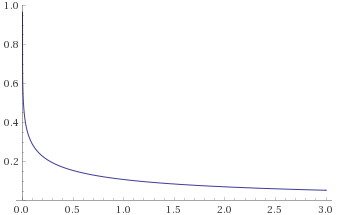
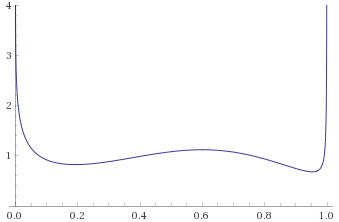
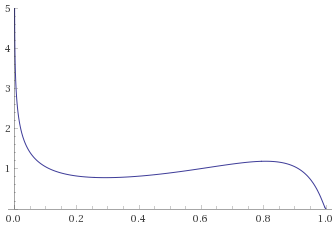
Here we have the opposite problem – distributions that look like they are going to zero under 
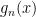

We are left with the Slow Localised category, which is epitomised by the Lognormal Distribution. The Lognormal is very commonly used in a lot of analysis, because its straightforward relation to the Gaussian Distribution makes it very easy to work with. Mandelbrot however, really doesn’t like the Lognormal Distribution – in fact he devotes an entire chapter of his book to why its overuse is so problematic. He states:
“It is beloved because it passes as mild: moments are easy to calculate and it is easy to take for granted that they play the same role as for the Gaussian. But they do not. They hide the difficulties due to skewness and long-tailedness behind limits that are overly sensitive and overly slowly attained”
“This distribution should be avoided. A major reason… is that a near-lognormal’s population moments are overly sensitive to departures from exact lognormalities. A second major reason… is that the sample moments are not to be trusted, because the sequential sample moments oscillate with sample size in erratic and unmanageable manner.”
It is this category then, that we are left with, having no easy families of transformations left to try. These distributions should have tails that are eventually heavier than any Slow Delocalised distribution, but lighter than any Pre-Wild distribution. This means, that if the above heuristics are correct, they should not be tamed by any transformation using
Of course, the issues we established with the Borderline Mild and Slow Delocalised distributions are very much relevant here. The heuristic may have been somewhat informative for the other categories of Slow randomness – allowing positive identification of many distributions that don’t require us to delve too deeply into any of the infinite families of transformations, and whose transforms don’t have behaviour at 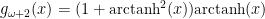
Lognormal Distribution [before, transform 1, transform 2]:
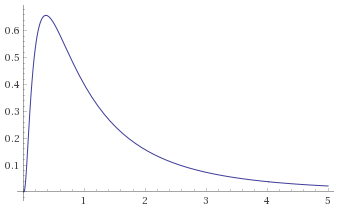
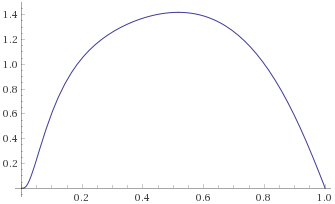
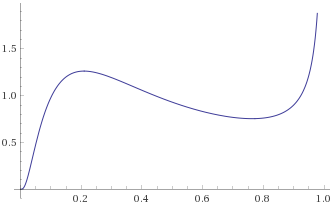

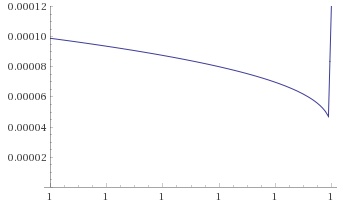
Arcsinh-Gaussian Distribution [before, transform 1, transform 2]:
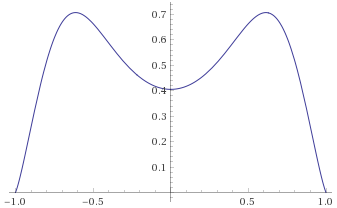
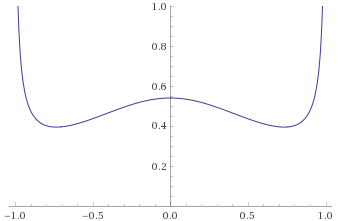
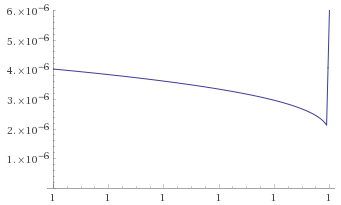
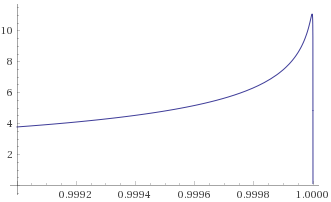
We can see that the graphs look the wrong way around – the distributions look like they are tamed by 
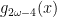
If we tried with transforms based on 
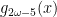
XI. Stability
Having trawled through all of the States of Randomness, it is worth noting a very important property of Wild, Aggressive and Extreme randomness – they no longer obey the classical Central Limit Theorem.
The Central Limit Theorem states that if you add n i.i.d (independent and identically distributed) random variables together, the sum of the variables will tend towards being distributed according to a Gaussian Distribution as 
If you have i.i.d. random variables that are distributed according to a Probability Density Function with tails that decay like 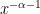


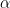
These Stable Distributions have the same kind of Paretian tails as the distributions that generated them, so for example, the sum of n random variables that were generated by a Student’s T Distribution with 1.5 degrees of freedom will tend towards being distributed according to a Stable Distribution with stability parameter 1.5 as
The stability parameter that defines the family of Stable Distributions can vary between
- Pre-Wild randomness (Paretian tails with
) falls under the classical Central Limit Theorem, so under these conditions all will tend towards the Stable Distribution with stability parameter 2 (the Gaussian Distribution)
- Wild randomness with
(e.g. Student’s T Distribution with 2 degrees of freedom, Fisk Distribution with shape parameter 2, Pareto Distribution with shape parameter 2 and Inverse-Chi-Squared distribution with 4 degrees of freedom) will actually still tend towards the Gaussian Distribution in this limit, however for any finite sum of n random variables, the sum’s distribution will still have undefined variance.
- Wild randomness with
and Aggressive randomness
will tend towards a non-Gaussian, heavy tailed Stable Distribution with stability parameter
in this limit.
- Extreme randomness is still not covered by this theorem, as Extreme distributions have tails that are even heavier than Paretian tails. These are rarely used distributions, but it does not appear to be known what their behaviour is in this limit.
Most Stable Distributions have Probability Density Functions that are not expressable in terms of elementary functions, which makes them rather hard to deal with (with the exception of the Gaussian, Cauchy and Levy distributions). Their stability under summation of random variables was a key feature that Mandelbrot was interested in however, due to his focus on fractals and self-similarity. If you have a stochastic process whose evolution over time is self-similar (for instance its movements over a day are indistinguishable from its movements over a year), which he hypothesised was the case for the stock market and commodity prices, you have a situation where the sum of multiple random variables (daily movements) must behave the same as the individual random variables themselves (minute by minute movements). In other words, random variables distributed according to a Stable Distribution.
XII. Conclusion
At this point, it is natural to ask what has been achieved by all of this. The claims above are not rigorously proven, therefore the transformation discussed is only a heuristic. Hopefully however, it provides a useful lens with which to view the tail behaviour of various distributions, giving more of an intuitive feel of how different heavy behave.
Whilst Mandelbrot’s book originates the concept, it is first and foremost an academic text from someone at the forefront of a field of study, which makes it unsurprisingly dense and impenetrable. It provides the basis for the taxonomy he developed, but is remarkably short on examples, which are often a good way to gain understanding of a topic. He did write another book aimed at a more general audience, that is much more accessible and gets across some of his ideas in this area. I highly recommend reading it, but unfortunately one thing that it doesn’t go into much detail on, is this taxonomy for classifying randomness.
Dealing with heavy tails is an area of probability that is hugely important for understanding real-world processes, and the tendency for people to try to shoe-horn their data into Gaussian or Lognormal models is likely due to the underdevelopment of tools for dealing with these other types of randomness. As such, I hope that the plethora of examples above is able to make the concepts slightly more accessible and encourage further exploration.
In summary, assuming that the behaviour of the transformation 
- Proper Mild Randomness
- Short-run Portioning is even for N=2
for
- Borderline Mild Randomness
- Short-run Portioning is concentrated
- Long-run Portioning becomes even, for some finite N
- The nth root of the nth moment grows like n
- Right-hand tail of the Survival Function decays like
for
for some
- Delocalised Slow Randomness
- The nth root of the nth moment grows like a power of n
- Right-hand tail of the Survival Function decays like
for some
for some
- Localised Slow Randomness
- The nth root of the nth moment grows faster than any power of n
- All moments still finite
- Right-hand tail of the Survival Function decays like
for some
- (In principle,
)
- (In principle,
for all
)
- Pre-wild Randomness
- Moments grow so fast that some higher moments are infinite
- The 2nd moment (variance) is still finite
- Long-run Portioning still becomes even, for a large enough finite N
- Right-hand tail of the Survival Function decays like
- Wild Randomness
- Even the 2nd moment is infinite, so the variance is not defined
- The 1st moment (mean) is still finite
- Long-run Portioning is concentrated for all N
- Right-hand tail of the Survival Function decays like
- Aggressive Randomness
- Even the 1st moment is undefined There exists some moment (possibly fractional)
- Right-hand tail of the Survival Function decays like
- Even the 1st moment is undefined There exists some moment (possibly fractional)
- Extreme Randomness
- All moments
- All moments
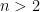
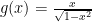
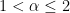
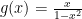
One Reply to “Heavy Tailed Distributions and the States of Randomness”
Amazing stuff!